 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchoring Emotions in Text: Robust Multimodal Fusion for Mimicry Intensity Estimation
Mar 16, 2026Estimating Emotional Mimicry Intensity (EMI) in naturalistic environments is a critical yet challenging task in affective computing. The primary difficulty lies in effectively modeling the complex, nonlinear temporal dynamics across highly heterogeneous modalities, especially when physical signals are corrupted or missing. To tackle this, we propose TAEMI (Text-Anchored Emotional Mimicry Intensity estimation), a novel multimodal framework designed for the 10th ABAW Competition. Motivated by the observation that continuous visual and acoustic signals are highly susceptible to transient environmental noise, we break the traditional symmetric fusion paradigm. Instead, we leverage textual transcript--which inherently encode a stable, time-independent semantic prior--as central anchors. Specifically, we introduce a Text-Anchored Dual Cross-Attention mechanism that utilizes these robust textual queries to actively filter out frame-level redundancies and align the noisy physical streams. Furthermore, to prevent catastrophic performance degradation caused by inevitably missing data in unconstrained real-world scenarios, we integrate Learnable Missing-Modality Tokens and a Modality Dropout strategy during training. Extensive experiments on the Hume-Vidmimic2 dataset demonstrate that TAEMI effectively captures fine-grained emotional variations and maintains robust predictive resilience under imperfect conditions. Our framework achieves a state-of-the-art mean Pearson correlation coefficient across six continuous emotional dimensions, significantly outperforming existing baseline methods.
Hierarchical Granularity Alignment and State Space Modeling for Robust Multimodal AU Detection in the Wild
Mar 11, 2026Facial Action Unit (AU) detection in in-the-wild environments remains a formidable challenge due to severe spatial-temporal heterogeneity, unconstrained poses, and complex audio-visual dependencies. While recent multimodal approaches have made progress, they often rely on capacity-limited encoders and shallow fusion mechanisms that fail to capture fine-grained semantic shifts and ultra-long temporal contexts. To bridge this gap, we propose a novel multimodal framework driven by Hierarchical Granularity Alignment and State Space Models.Specifically, we leverage powerful foundation models, namely DINOv2 and WavLM, to extract robust and high-fidelity visual and audio representations, effectively replacing traditional feature extractors. To handle extreme facial variations, our Hierarchical Granularity Alignment module dynamically aligns global facial semantics with fine-grained local active patches. Furthermore, we overcome the receptive field limitations of conventional temporal convolutional networks by introducing a Vision-Mamba architecture. This approach enables temporal modeling with O(N) linear complexity, effectively capturing ultra-long-range dynamics without performance degradation. A novel asymmetric cross-attention mechanism is also introduced to deeply synchronize paralinguistic audio cues with subtle visual movements.Extensive experiments on the challenging Aff-Wild2 dataset demonstrate that our approach significantly outperforms existing baselines, achieving state-of-the-art performance. Notably, this framework secured top rankings in the AU Detection track of the 10th Affective Behavior Analysis in-the-wild Competition.
Solution to the 10th ABAW Expression Recognition Challenge: A Robust Multimodal Framework with Safe Cross-Attention and Modality Dropout
Mar 09, 2026Emotion recognition in real-world environments is hindered by partial occlusions, missing modalities, and severe class imbalance. To address these issues, particularly for the Affective Behavior Analysis in-the-wild (ABAW) Expression challenge, we propose a multimodal framework that dynamically fuses visual and audio representations. Our approach uses a dual-branch Transformer architecture featuring a safe cross-attention mechanism and a modality dropout strategy. This design allows the network to rely on audio-based predictions when visual cues are absent. To mitigate the long-tail distribution of the Aff-Wild2 dataset, we apply focal loss optimization, combined with a sliding-window soft voting strategy to capture dynamic emotional transitions and reduce frame-level classification jitter. Experiments demonstrate that our framework effectively handles missing modalities and complex spatiotemporal dependencies, achieving an accuracy of 60.79% and an F1-score of 0.5029 on the Aff-Wild2 validation set.
Learning to Ideate for Machine Learning Engineering Agents
Jan 24, 2026Existing machine learning engineering (MLE) agents struggle to iteratively optimize their implemented algorithms for effectiveness. To address this, we introduce MLE-Ideator, a dual-agent framework that separates ideation from implementation. In our system, an implementation agent can request strategic help from a dedicated Ideator. We show this approach is effective in two ways. First, in a training-free setup, our framework significantly outperforms implementation-only agent baselines on MLE-Bench. Second, we demonstrate that the Ideator can be trained with reinforcement learning (RL) to generate more effective ideas. With only 1K training samples from 10 MLE tasks, our RL-trained Qwen3-8B Ideator achieves an 11.5% relative improvement compared to its untrained counterpart and surpasses Claude Sonnet 3.5. These results highlights a promising path toward training strategic AI systems for scientific discovery.
Gaming the Judge: Unfaithful Chain-of-Thought Can Undermine Agent Evaluation
Jan 21, 2026Large language models (LLMs) are increasingly used as judges to evaluate agent performance, particularly in non-verifiable settings where judgments rely on agent trajectories including chain-of-thought (CoT) reasoning. This paradigm implicitly assumes that the agent's CoT faithfully reflects both its internal reasoning and the underlying environment state. We show this assumption is brittle: LLM judges are highly susceptible to manipulation of agent reasoning traces. By systematically rewriting agent CoTs while holding actions and observations fixed, we demonstrate that manipulated reasoning alone can inflate false positive rates of state-of-the-art VLM judges by up to 90% across 800 trajectories spanning diverse web tasks. We study manipulation strategies spanning style-based approaches that alter only the presentation of reasoning and content-based approaches that fabricate signals of task progress, and find that content-based manipulations are consistently more effective. We evaluate prompting-based techniques and scaling judge-time compute, which reduce but do not fully eliminate susceptibility to manipulation. Our findings reveal a fundamental vulnerability in LLM-based evaluation and highlight the need for judging mechanisms that verify reasoning claims against observable evidence.
Skill-Aware Data Selection and Fine-Tuning for Data-Efficient Reasoning Distillation
Jan 15, 2026Large reasoning models such as DeepSeek-R1 and their distilled variants achieve strong performance on complex reasoning tasks. Yet, distilling these models often demands large-scale data for supervised fine-tuning (SFT), motivating the pursuit of data-efficient training methods. To address this, we propose a skill-centric distillation framework that efficiently transfers reasoning ability to weaker models with two components: (1) Skill-based data selection, which prioritizes examples targeting the student model's weaker skills, and (2) Skill-aware fine-tuning, which encourages explicit skill decomposition during problem solving. With only 1,000 training examples selected from a 100K teacher-generated corpus, our method surpasses random SFT baselines by +1.6% on Qwen3-4B and +1.4% on Qwen3-8B across five mathematical reasoning benchmarks. Further analysis confirms that these gains concentrate on skills emphasized during training, highlighting the effectiveness of skill-centric training for efficient reasoning distillation.
LiveOIBench: Can Large Language Models Outperform Human Contestants in Informatics Olympiads?
Oct 10, 2025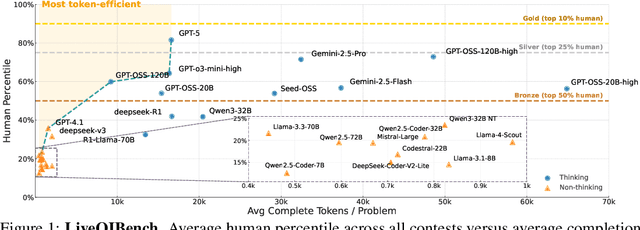
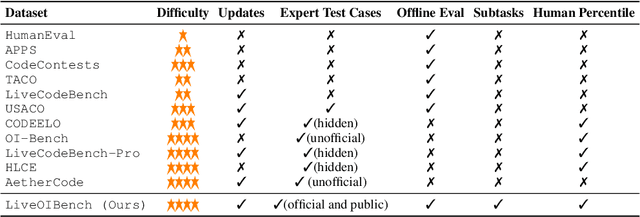
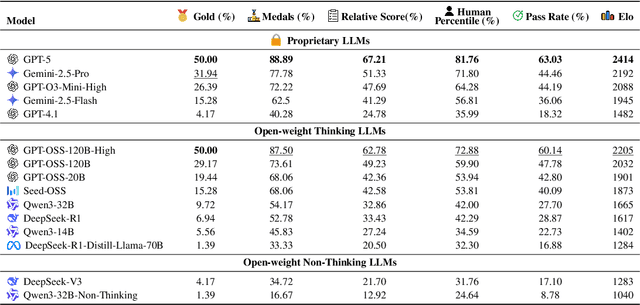
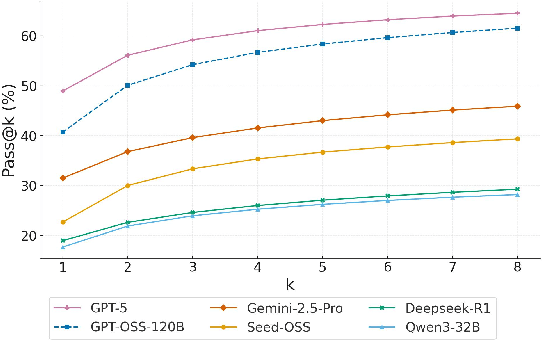
Competitive programming problems increasingly serve as valuable benchmarks to evaluate the coding capabilities of large language models (LLMs) due to their complexity and ease of verification. Yet, current coding benchmarks face limitations such as lack of exceptionally challenging problems, insufficient test case coverage, reliance on online platform APIs that limit accessibility. To address these issues, we introduce LiveOIBench, a comprehensive benchmark featuring 403 expert-curated Olympiad-level competitive programming problems, each with an average of 60 expert-designed test cases. The problems are sourced directly from 72 official Informatics Olympiads in different regions conducted between 2023 and 2025. LiveOIBench distinguishes itself through four key features: (1) meticulously curated high-quality tasks with detailed subtask rubrics and extensive private test cases; (2) direct integration of elite contestant performance data to enable informative comparison against top-performing humans; (3) planned continuous, contamination-free updates from newly released Olympiad problems; and (4) a self-contained evaluation system facilitating offline and easy-to-reproduce assessments. Benchmarking 32 popular general-purpose and reasoning LLMs, we find that GPT-5 achieves a notable 81.76th percentile, a strong result that nonetheless falls short of top human contestant performance, who usually place above 90th. In contrast, among open-weight reasoning models, GPT-OSS-120B achieves only a 60th percentile, underscoring significant capability disparities from frontier closed models. Detailed analyses indicate that robust reasoning models prioritize precise problem analysis over excessive exploration, suggesting future models should emphasize structured analysis and minimize unnecessary exploration. All data, code, and leaderboard results will be made publicly available on our website.
Contrastive Learning with Spectrum Information Augmentation in Abnormal Sound Detection
Sep 19, 2025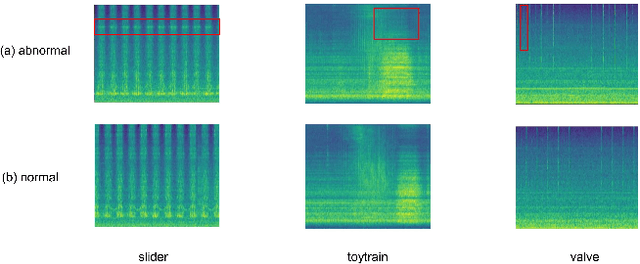

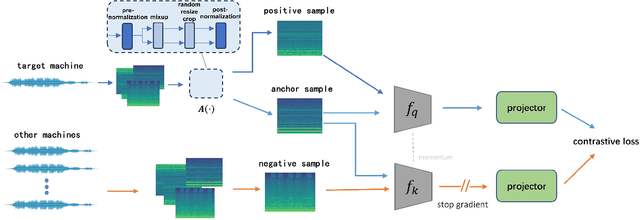

The outlier exposure method is an effective approach to address the unsupervised anomaly sound detection problem. The key focus of this method is how to make the model learn the distribution space of normal data. Based on biological perception and data analysis, it is found that anomalous audio and noise often have higher frequencies. Therefore, we propose a data augmentation method for high-frequency information in contrastive learning. This enables the model to pay more attention to the low-frequency information of the audio, which represents the normal operational mode of the machine. We evaluated the proposed method on the DCASE 2020 Task 2. The results showed that our method outperformed other contrastive learning methods used on this dataset. We also evaluated the generalizability of our method on the DCASE 2022 Task 2 dataset.
MLRC-Bench: Can Language Agents Solve Machine Learning Research Challenges?
Apr 13, 2025



Existing evaluation of large language model (LLM) agents on scientific discovery lacks objective baselines and metrics to assess the viability of their proposed methods. To address this issue, we introduce MLRC-Bench, a benchmark designed to quantify how effectively language agents can tackle challenging Machine Learning (ML) Research Competitions. Our benchmark highlights open research problems that demand novel methodologies, in contrast to recent benchmarks such as OpenAI's MLE-Bench (Chan et al., 2024) and METR's RE-Bench (Wijk et al., 2024), which focus on well-established research tasks that are largely solvable through sufficient engineering effort. Unlike prior work, e.g., AI Scientist (Lu et al., 2024b), which evaluates the end-to-end agentic pipeline by using LLM-as-a-judge, MLRC-Bench measures the key steps of proposing and implementing novel research methods and evaluates them with newly proposed rigorous protocol and objective metrics. Our curated suite of 7 competition tasks reveals significant challenges for LLM agents. Even the best-performing tested agent (gemini-exp-1206 under MLAB (Huang et al., 2024a)) closes only 9.3% of the gap between baseline and top human participant scores. Furthermore, our analysis reveals a misalignment between the LLM-judged innovation and their actual performance on cutting-edge ML research problems. MLRC-Bench is a dynamic benchmark, which is designed to continually grow with new ML competitions to encourage rigorous and objective evaluations of AI's research capabilities.
Nano-3D: Metasurface-Based Neural Depth Imaging
Mar 20, 2025



Depth imaging is a foundational building block for broad applications, such as autonomous driving and virtual/augmented reality. Traditionally, depth cameras have relied on time-of-flight sensors or multi-lens systems to achieve physical depth measurements. However, these systems often face a trade-off between a bulky form factor and imprecise approximations, limiting their suitability for spatially constrained scenarios. Inspired by the emerging advancements of nano-optics, we present Nano-3D, a metasurface-based neural depth imaging solution with an ultra-compact footprint. Nano-3D integrates our custom-fabricated 700 nm thick TiO2 metasurface with a multi-module deep neural network to extract precise metric depth information from monocular metasurface-polarized imagery. We demonstrate the effectiveness of Nano-3D with both simulated and physical experiments. We hope the exhibited success paves the way for the community to bridge future graphics systems with emerging nanomaterial technologies through novel computational approaches.